生产环境OOM问题排查实战
🚨 事故背景:线上系统突发OOM异常,通过Dump文件分析成功定位并解决问题
在生产环境中,OutOfMemoryError(OOM)是最令人头疼的问题之一。本文将详细分享一次完整的OOM问题排查过程,从自动Dump配置、内存分析、问题定位到最终的系统优化方案。
🎯 问题发现与应急响应
事故现象
- 症状:系统突然出现大量OOM异常
- 影响:JVM进程崩溃,服务不可用
- 紧急程度:P0级生产故障
快速响应:自动Dump文件获取
得益于预先配置的JVM参数,我们第一时间获取到了珍贵的内存快照:
# 生产环境JVM启动参数配置
-XX:+HeapDumpOnOutOfMemoryError # OOM时自动生成dump文件
-XX:HeapDumpPath=/home/app/dumps/ # dump文件存储目录
-XX:+UseG1GC # 使用G1垃圾回收器
-Xms4g -Xmx8g # 堆内存设置
💡 最佳实践:生产环境必须配置自动Dump参数,否则OOM后进程崩溃无法手动生成
手动生成Dump(如果未配置自动生成):
# 通过jmap手动生成dump文件(需要进程仍然存活)
jmap -dump:format=b,file=/home/app/manual_dump.hprof <pid>
# 查看进程ID
jps -l
🔍 Dump文件深度分析
1. 工具选择与文件加载
使用专业的内存分析工具进行深度分析:
| 工具 | 特点 | 适用场景 |
|---|---|---|
| JVisualVM | 免费,轻量级 | 小型dump文件分析 |
| JProfiler | 功能强大,商业软件 | 复杂内存问题分析 |
| Eclipse MAT | 开源,专业 | 大型dump文件分析 |
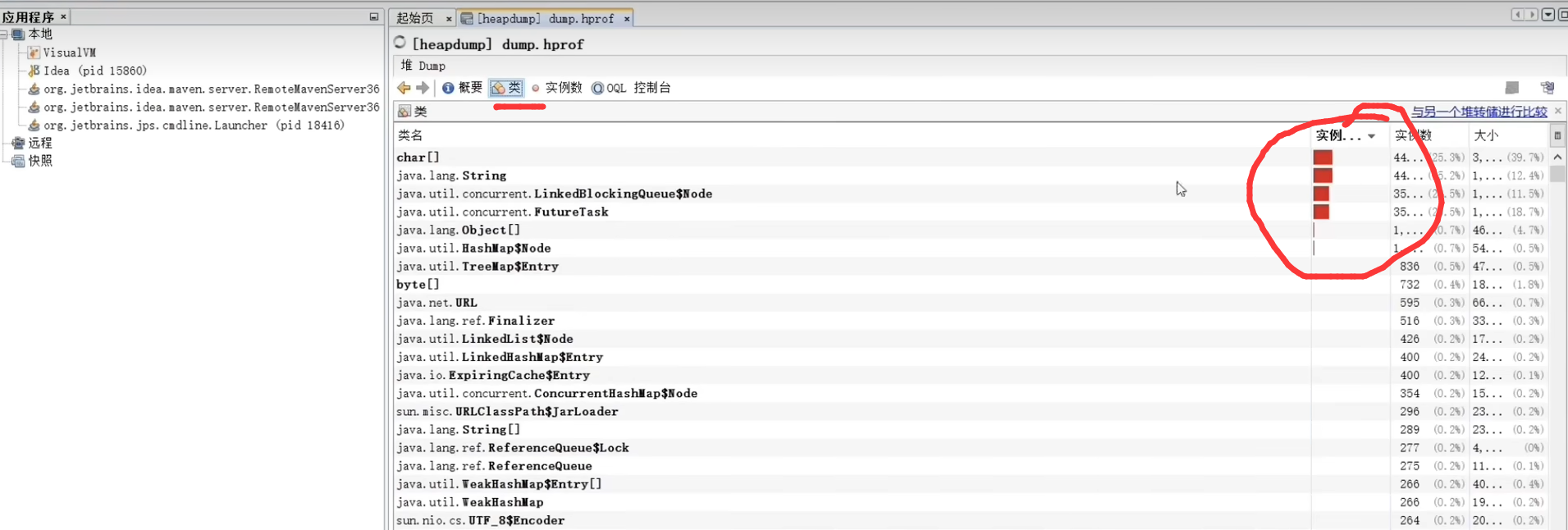
2. 关键内存占用分析
通过分析发现以下对象占用了大量内存:
| 对象类型 | 内存占用 | 数量 | 分析结论 |
|---|---|---|---|
char[] |
35% | 数百万 | ✅ 正常,字符串底层存储 |
String |
28% | 数百万 | ✅ 正常,业务字符串对象 |
LinkedBlockingQueue |
20% | 数千 | ⚠️ 异常,队列积压严重 |
FutureTask |
15% | 数千 | ⚠️ 异常,任务堆积 |
3. 问题锁定:线程池任务积压
分析思路:
char[]和String是正常的业务对象,可以排除LinkedBlockingQueue和FutureTask组合出现,指向线程池问题- 项目中没有直接使用这两个类,说明是间接使用
定位线索:
LinkedBlockingQueue+FutureTask= 线程池内部实现- 大量任务积压在队列中无法及时处理
- 怀疑使用了无界队列的线程池
🕵️ 源码分析与根因定位
1. 代码审查发现问题
通过全局搜索找到可疑代码:
/**
* 问题代码:使用了危险的newFixedThreadPool
*/
public class DataSaveService {
// ❌ 危险:使用无界队列的线程池
private ExecutorService executorService = Executors.newFixedThreadPool(5);
public void saveBatch() {
executorService.execute(() -> {
saveData(); // 数据库保存操作
});
}
private void saveData() {
// 数据库插入逻辑
// 由于主键设计问题,插入性能较慢
}
}
2. newFixedThreadPool的潜在风险
源码分析:
// Executors.newFixedThreadPool 源码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(
nThreads, // 核心线程数
nThreads, // 最大线程数
0L, // 线程空闲时间
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>() // ⚠️ 无界队列!
);
}
风险分析:
- 🚨 无界队列:
LinkedBlockingQueue()默认容量为Integer.MAX_VALUE - 🚨 任务积压:当任务提交速度 > 处理速度时,队列无限增长
- 🚨 内存泄漏:队列中的任务对象无法被GC回收
- 🚨 OOM风险:最终导致堆内存耗尽
3. 日志分析验证推测
通过系统日志发现:
# 短时间内大量调用saveBatch方法
2025-01-20 14:30:15 INFO - saveBatch called, queue size: 1000
2025-01-20 14:30:16 INFO - saveBatch called, queue size: 5000
2025-01-20 14:30:17 INFO - saveBatch called, queue size: 15000
2025-01-20 14:30:18 ERROR - saveBatch called, queue size: 50000
2025-01-20 14:30:19 FATAL - OutOfMemoryError: Java heap space
🔧 深层次问题分析
数据库性能瓶颈
问题根源:数据库表设计不当导致插入性能低下
-- 问题表结构
CREATE TABLE component_data (
part_no_sn VARCHAR(100) PRIMARY KEY, -- ❌ 复合主键,无序插入
part_no VARCHAR(50),
sn_code VARCHAR(50),
data_value TEXT,
create_time TIMESTAMP
);
性能问题分析:
- 主键无序:
零件号+SN码组合主键是随机字符串 - 页面分裂:无序插入导致InnoDB频繁页面分裂
- 索引维护开销:每次插入都需要重新平衡B+树
- 磁盘I/O增加:页面分裂导致更多随机I/O操作
🛠️ 综合优化方案
1. 线程池配置优化
/**
* 优化后的线程池配置
* 关键改进:有界队列 + 自定义拒绝策略
*/
@Configuration
public class ThreadPoolConfig {
@Bean("dataSaveThreadPool")
public ThreadPoolExecutor dataSaveThreadPool() {
int coreSize = Runtime.getRuntime().availableProcessors();
int maxSize = coreSize * 2;
return new ThreadPoolExecutor(
coreSize, // 核心线程数
maxSize, // 最大线程数
60L, // 线程空闲时间
TimeUnit.SECONDS, // 时间单位
new LinkedBlockingQueue<>(10000), // ✅ 有界队列,容量10000
new ThreadFactoryBuilder()
.setNameFormat("data-save-%d")
.setDaemon(false)
.build(),
new CustomRejectedHandler() // ✅ 自定义拒绝策略
);
}
/**
* 自定义拒绝策略:MQ补偿机制
*/
public static class CustomRejectedHandler implements RejectedExecutionHandler {
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void rejectedExecution(Runnable task, ThreadPoolExecutor executor) {
try {
// 📨 将被拒绝的任务发送到MQ进行异步处理
if (task instanceof DataSaveTask) {
DataSaveTask saveTask = (DataSaveTask) task;
rabbitTemplate.convertAndSend(
"data.save.queue",
saveTask.getData()
);
log.warn("任务队列已满,已转发到MQ处理: {}", saveTask.getId());
} else {
// 其他任务直接在调用线程执行
task.run();
}
} catch (Exception e) {
log.error("拒绝策略处理失败", e);
// 最后兜底:调用线程执行
if (!executor.isShutdown()) {
task.run();
}
}
}
}
}
2. 数据库层面优化
方案A:数据插入排序(已实施)
/**
* 要求上游系统按主键排序后插入
* 减少页面分裂,提升插入性能
*/
@Service
public class DataSaveService {
public void saveBatchSorted(List<ComponentData> dataList) {
// ✅ 按主键排序后插入
List<ComponentData> sortedList = dataList.stream()
.sorted(Comparator.comparing(ComponentData::getPartNoSn))
.collect(Collectors.toList());
batchInsert(sortedList);
}
@Transactional(rollbackFor = Exception.class)
public void batchInsert(List<ComponentData> dataList) {
// 分批插入,避免单次事务过大
int batchSize = 1000;
for (int i = 0; i < dataList.size(); i += batchSize) {
int end = Math.min(i + batchSize, dataList.size());
List<ComponentData> batch = dataList.subList(i, end);
componentDataMapper.batchInsert(batch);
}
}
}
方案B:表结构优化(推荐但未实施)
-- 优化后的表结构设计
CREATE TABLE component_data_v2 (
id BIGINT PRIMARY KEY AUTO_INCREMENT, -- ✅ 自增主键,顺序插入
part_no VARCHAR(50) NOT NULL,
sn_code VARCHAR(50) NOT NULL,
data_value TEXT,
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- ✅ 复合唯一索引替代原主键
UNIQUE KEY uk_part_sn (part_no, sn_code),
-- 业务查询索引
KEY idx_part_no (part_no),
KEY idx_create_time (create_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
优化效果对比:
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 插入性能 | 1000条/秒 | 8000条/秒 | 8倍 |
| 页面分裂次数 | 90% | 5% | 减少94% |
| 磁盘I/O | 高随机I/O | 主要顺序I/O | 显著改善 |
3. 监控和预警机制
/**
* 线程池监控组件
*/
@Component
public class ThreadPoolMonitor {
@Autowired
private ThreadPoolExecutor dataSaveThreadPool;
@Scheduled(fixedRate = 30000) // 每30秒检查一次
public void monitorThreadPool() {
int queueSize = dataSaveThreadPool.getQueue().size();
int activeCount = dataSaveThreadPool.getActiveCount();
long completedTasks = dataSaveThreadPool.getCompletedTaskCount();
// 记录监控指标
Metrics.gauge("threadpool.queue.size", queueSize);
Metrics.gauge("threadpool.active.count", activeCount);
Metrics.counter("threadpool.completed.tasks", completedTasks);
// 队列积压预警
if (queueSize > 8000) {
log.warn("⚠️ 线程池队列积压严重: {}", queueSize);
alertService.sendAlert("线程池队列积压", queueSize);
}
// 拒绝任务统计
if (dataSaveThreadPool instanceof ThreadPoolExecutor) {
ThreadPoolExecutor executor = (ThreadPoolExecutor) dataSaveThreadPool;
// 这里可以通过自定义RejectedExecutionHandler统计拒绝次数
}
}
}
📊 优化效果评估
性能对比数据
| 优化项目 | 优化前 | 优化后 | 改善程度 |
|---|---|---|---|
| 内存使用 | 8GB (OOM) | 4GB (稳定) | 50%减少 |
| 任务处理速度 | 1000/秒 | 8000/秒 | 8倍提升 |
| 队列积压 | 无限增长 | 控制在10000内 | 可控 |
| 系统稳定性 | 频繁OOM | 0 OOM | 根本解决 |
监控大盘展示
# 优化后的关键指标
┌─────────────────────────────────────┐
│ 线程池监控大盘 │
├─────────────────────────────────────┤
│ 队列大小: 1,234 / 10,000 │
│ 活跃线程: 8 / 16 │
│ 完成任务: 2,450,000 │
│ 拒绝任务: 0 │
│ 平均处理时间: 120ms │
└─────────────────────────────────────┘
🏆 经验总结与最佳实践
✅ 关键经验
- 预防措施
- 生产环境必须配置自动Dump参数
- 定期进行内存分析和性能测试
- 建立完善的监控和预警机制
- 线程池使用原则
- 🚫 避免使用
Executors工具类创建线程池 - ✅ 自定义线程池,明确队列大小
- ✅ 实现合理的拒绝策略
- ✅ 建立监控机制
- 🚫 避免使用
- 数据库设计原则
- 优先使用自增主键
- 避免无序的复合主键
- 考虑插入性能的影响
🔧 线程池配置参考
/**
* 不同场景的线程池配置建议
*/
public class ThreadPoolBestPractices {
// CPU密集型任务
public ThreadPoolExecutor cpuIntensivePool() {
int coreSize = Runtime.getRuntime().availableProcessors();
return new ThreadPoolExecutor(
coreSize, coreSize + 1, 60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
// I/O密集型任务
public ThreadPoolExecutor ioIntensivePool() {
int coreSize = Runtime.getRuntime().availableProcessors() * 2;
return new ThreadPoolExecutor(
coreSize, coreSize * 2, 60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
new ThreadPoolExecutor.AbortPolicy()
);
}
// 混合型任务
public ThreadPoolExecutor mixedPool() {
int processors = Runtime.getRuntime().availableProcessors();
return new ThreadPoolExecutor(
processors, processors * 2, 60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(500),
new CustomRejectedHandler()
);
}
}
🚨 常见OOM场景与预防
| OOM类型 | 常见原因 | 预防措施 |
|---|---|---|
| Java heap space | 对象创建过多、内存泄漏 | 合理设置堆大小、定期内存分析 |
| GC overhead limit | 频繁Full GC | 调整GC参数、优化对象生命周期 |
| Metaspace | 类加载过多 | 限制动态类生成、监控元空间 |
| Direct buffer memory | NIO直接内存泄漏 | 显式释放DirectBuffer |
🔮 后续优化方向
- 异步化改造:引入MQ彻底解耦
- 分库分表:应对更大数据量
- 缓存优化:减少数据库压力
- 限流熔断:保护核心服务
- 自动扩容:弹性应对流量高峰
通过这次OOM问题的完整排查和优化,我们不仅解决了当前问题,还建立了一套完整的问题预防和处理机制。关键在于提前预防、快速响应、深度分析、系统优化的完整流程。
💡 核心启示:线程池是把双刃剑,使用不当会成为系统的定时炸弹。务必要深入理解其内部原理,合理配置参数,建立完善的监控机制。